Belajar ala Model Machine Learning
Halo semua!
Kembali lagi nih, belajar tentang ‘Machine Learning’. Kalau sebelum-sebelumnya kita mengerti bahwa sebuah mesin/model bisa belajar dengan sendirinya apabila kita berikan data, dan juga ada yang namanya `model.fit` di Tensorflow yang membuat model yang kita rancang belajar sendiri, sekarang kita akan belajar lebih dalam lagi, sebenarnya apa sih yang dilakukan mesin/model ini sehingga dia bisa jago?
Mari kita mulai nih dengan regresi linier. Regresi linier memiliki tugas untuk mencari garis yang linear untuk menggambarkan seluruh sebaran data. Kalau kita ingat-ingat, rumus garis adalah y = mx + b, dimana x adalah input, m adalah variabel kemiringan dan b adalah intersep.
Mari kita bayangkan, kita memiliki banyak data yang tersebar seperti pada contoh gambar 1 pada scatter plot, dimana tugas kita adalah untuk mencari garis yang dapat merepresentasikan hampir semua data yang ada. Secara praktikal, cara menemukan garis tersebut adalah dengan mencari nilai kemiringan (m) dan intersep (b). Mungkin kalau kita masih belum mengenal machine learning, kita akan mengambil penggaris dan mencoba membuat garis yang pas.
Tapi kita tidak akan melakukan itu, karena kita sudah mengenal machine learning. Kita akan membuatnya lebih sistematis, yaitu dengan memanfaatkan fungsi error. Mean Squared Error (MSE) merupakan fungsi yang bisa mendefinisikan kesalahan / error pada sebuah garis regresi yang ada. Caranya adalah dengan menghitung selisih dari nilai sebenarnya (nilai y dari titik poin data) dengan nilai prediksi (nilai y yang didapat dengan memasukkan nilai x ke dalam fungsi garis mx+b).
Apabila seluruh titik berada di setiap garis, maka nilai MSE ini akan sama dengan 0, yang mana ini adalah nilai optimal yang ingin kita capai. Sehingga tujuan dari learning adalah dengan meminimalkan nilai loss. Caranya? Mari kita sedikit mengulas kalkulus. Kalau masih ingat pelajaran SMA atau kuliah, kita bisa mencari nilai maksimum atau minimum dengan cara mendapatkan turunan dari sebuah fungsi yang sama dengan 0. Dimana apabila kita memiliki lebih dari satu variabel dan harus mencari turunannya, maka fungsi akan disebut dengan gradient. Tapi baik satu ataupun lebih dari satu variabel, keduanya memiliki ide dasar yang sama, yaitu dengan mencari gradien (turunan) dan atur nilainya menjadi 0, untuk menemukan parameter / bobot.
Sudah cukup pusing? Tenang, sama 😛 Tapi jangan khawatir, sambil terus belajar dan menggali tentang ini, kita dimudahkan dengan adanya Keras dan Tensorflow, karena Tensorflow akan mengalkulasi nilai gradien dari seluruh bobot di model kita dan akan melakukan training kepada model menggunakan nilai gradien tsb untuk mencari nilai loss minimum.
Nah untuk regresi logistik, kita memerlukan metode lain yaitu Gradient Descent. Apa itu?
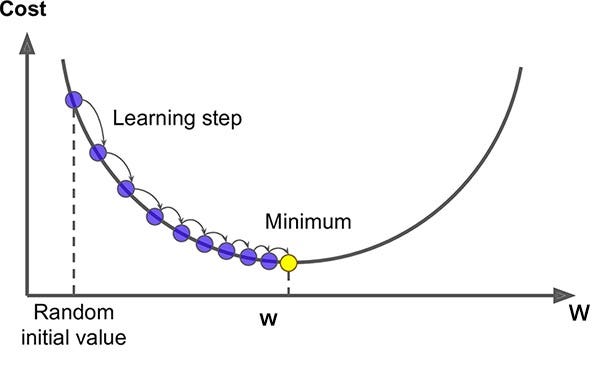
Mari bahas sedikit (karena nanti kita akan membahas topik ini lebih detail di post-post berikutnya!). Pada awalnya, nilai W dan B akan dipilih acak dan nilai ini tidak selalu membuat nilai loss kecil. Maka dari itu, kita akan mencari gradien dari loss W (∇w_J) dan B (∇b_J), lalu mengambil langkah kecil (dalam bentuk learning rate) untuk memperbarui nilai keduanya di setiap iterasi. Pada setiap langkah / iterasi, loss akan berkurang.
w,b = randomly initializedFor epoch in range(epochs): w = w — η * ∇w J b = b — η * ∇b J
Kalian bisa bayangkan inilah yang sebenarnya terjadi hanya pada 1 fungsi fit pada tensorflow keras. Pada persamaan tersebut eta (η) merupakan learning rate yang mendefinisikan seberapa cepat atau lambat kita ingin melatih model kita. Mengapa mempengaruhi lama dan cepat? Karena apabila kita memberinya nilai besar, maka nilai w dan b akan berubah dengan signifikan, sebaliknya, jika kita memberikan nilai kecil maka setiap epoch, nilai w dan b akan berubah sedikit demi sedikit. Nilai ini sangat penting karena jika tidak mendefinisikannya dengan benar, maka kita akan kesulitan untuk mendapatkan nilai optimum dan model tidak akan berjalan dengan baik.
Sayangnya belum ada metode yang secara langsung untuk memilih nilai ini. Pada umumnya nilai ini disebut hyperparameter, karena nilai ini adalah parameter tapi bukan bagian dari model. Cara menentukan nilai optimumnya adalah dengan trial and errors, dan semakin sering kita “bermain-main” dengan model, maka kita akan mendapatkan intuisi. Namun, kita juga dapat mencari referensi dari penelitian atau proses training yang sudah dilakukan sebelumnya.
Seperti yang kita lihat di gambar 5, memilih learning rate yang terlalu besar akan mempercepat waktu pelatihan namun loss akan melonjak dengan cepat pula. Ini disebabkan karena kita melewatkan nilai minimum dengan mengubah nilai parameter terlalu besar.
Namun, apabila kita memilih nilai terlalu rendah (garis biru pada gambar 6), kita mungkin bisa mendapatkan loss yang rendah namun membutuhkan waktu yang lama. Tidak hanya itu, bisa jadi kita terjebak di nilai sub optimal point. Namun hati-hati, apabila kita memberikan nilai yang sedikit lebih tinggi (garis hijau pada gambar 6), maka terkadang kita bisa melihat model kita konvergen namun hanya pada `sub optimal value`. Nilai yang baik berada di antara 2 nilai ini, seperti pada garis bewarna merah pada gambar 6, yaitu nilai terbaik untuk learning rate sehingga dapat menghasilkan model dengan loss seminimum mungkin. Pencarian ini yang nantinya bisa dilakukan sebagai proses eksperimen, dengan mencoba menggunakan nilai yang umumnya merupakan pangkat 10, contoh 0,1 kemudian 0,01 dan seterusnya.
Sekian belajar kita tentang bagaimana model belajar dan mendapatkan loss seminimum mungkin. Apabila ada koreksi dan masukan, jangan malu-malu untuk komentar ya. Sampai jumpa dan terima kasih!

{kind=link}